使用指南
Training 与 Sampling
MinT 使用 LoRA(Low-Rank Adaptation) 进行高效 fine-tune。核心思路:冻结基座模型 weight,仅训练附加的低秩适配器矩阵。
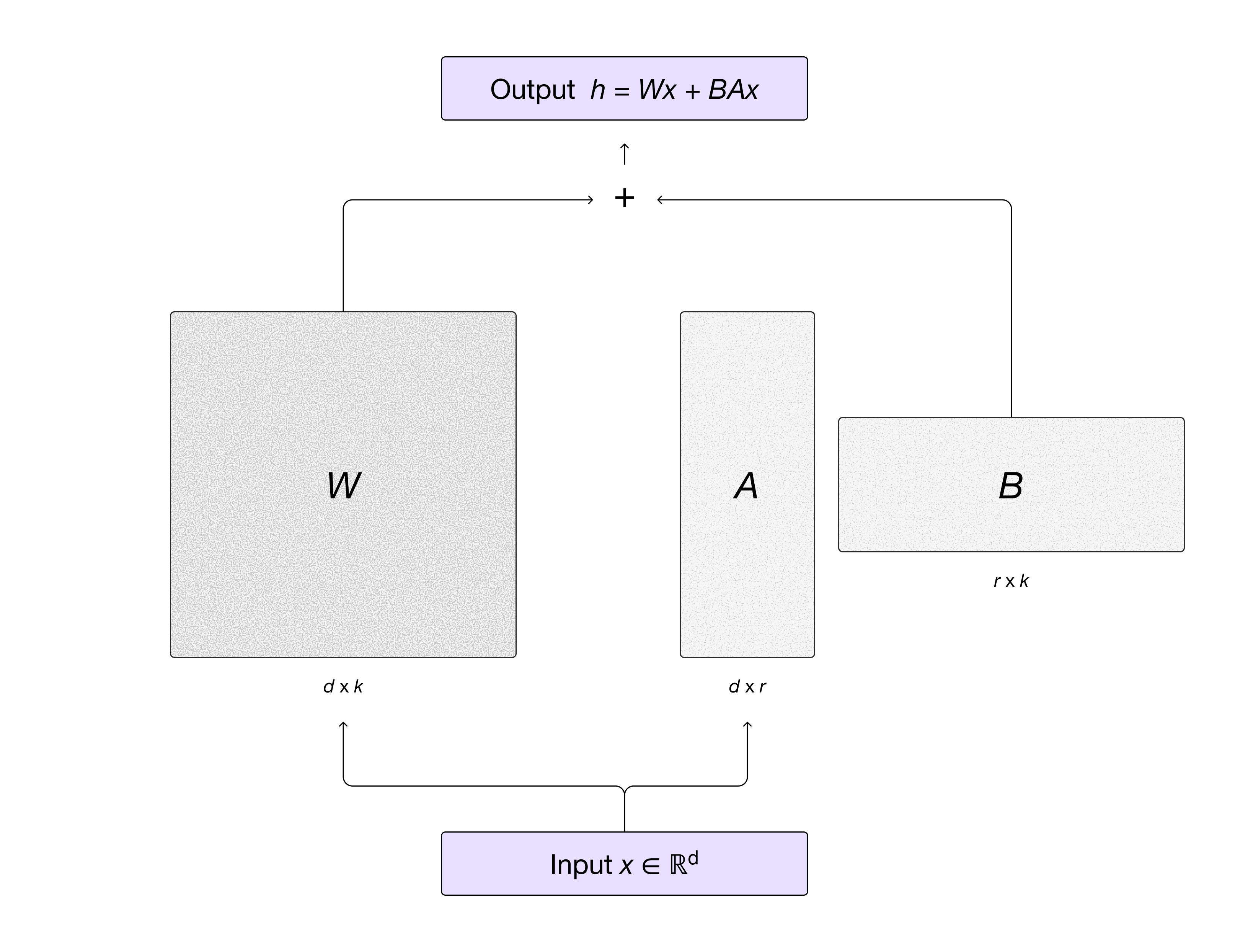
输出变为 h = Wx + BAx,其中 W 冻结,只有低秩矩阵 A 和 B 参与训练。显著降低显存和计算开销。
创建 Training Client
import mint
service_client = mint.ServiceClient()
training_client = service_client.create_lora_training_client(
base_model="Qwen/Qwen3-4B-Instruct-2507"
)请从当前模型列表中选择 base_model。
数据准备
将数据转换为 Datum 对象,包含 model input 和 loss 参数:
- 分别 tokenize prompt 和 completion
- 分配 weight(prompt 为 0,target 为 1)
- 构造 shifted token 序列用于 next-token prediction
Training 循环
梯度清零由服务器自动处理。正确的模式:
for _ in range(6):
fwdbwd_future = training_client.forward_backward(examples, "cross_entropy")
optim_future = training_client.optim_step(types.AdamParams(learning_rate=1e-4))不要在 MinT 训练循环里调用 zero_grad_async()。梯度清零由服务器自动处理。
Sampling
训练后创建 sampling client 生成输出:
sampling_client = training_client.save_weights_and_get_sampling_client(name='model')
result = sampling_client.sample(prompt=prompt, sampling_params=params, num_samples=8)会话超时
Sampling 会话有 30 分钟不活动超时。每次 sampling 请求会自动刷新会话。
对于长时间训练(两次 sample 间隔 >25 分钟),每个 batch 创建新的 sampling client:
for batch in range(num_batches):
# 每个 batch 创建新会话
sampling_client = training_client.save_weights_and_get_sampling_client()
# 在 25 分钟内完成 sampling
for step in range(max_steps):
result = await sampling_client.sample_async(...)
# 训练更新
await training_client.forward_backward_async(...)
await training_client.optim_step_async(...)参见 限制与配额 了解所有超时值。
Logprobs
可获取 token 概率:
include_prompt_logprobs=True:返回 prompt token 的 logprobstopk_prompt_logprobs=k:返回每个位置的 top-k 候选 token